이전 포스트에서 운영체제의 핵심 기능 중 하나인 memory management를 살펴보았다.
하지만 memory management의 고질적인 문제 중 하나는 역시 "메모리 부족" 사태이다.
이를 해결하기 위한 것이 바로 가상 메모리 기법이다.
Virtual Memory Management
: main memory와 disk 사이를 번갈아가며 메모리를 교체하는 swapping이 핵심이다.
따라서 main memory보다 훨씬 더 많은 메모리가 있는 것 처럼 여길 수 있다.
그럼 이 방법은 어떤 방식으로 이루어질까?
Background
virtual memory management는 logical address와 physical address를 분리한다.
그 이유는 한번에 프로그램은 모든 코드를 필요로 하지 않는다. 수행하는 부분 부분이 필요하기 때문이다.
따라서 필요한 부분 부분을 어떤 기법을 사용할 것인지에 따라 다음과 같이 구분된다.
- implement by demand segmentation
- implement by demand paging
virtual memory management: swapping

physical memory에 프로그램이 다 올라와야 실행되는 것은 누구나 다 아는 사실이다.
하지만 모든 코드가 다 필요할까? 그것은 아니다.
따라서 실행되는데 필요한 부분들만 physical memory에 올려두고 나머지는 필요한 순간에 disk에서 찾아서 physical memory에서 필요 없어진 page or sement와 교체하면 된다. 이것이 swapping, 즉 교체이다.
이때 필요한 page를 main memory에 올리는 것이 Demand Page 방식이다.
그렇다면 이 Demand Page는 왜 가능한 것일까?
Demand Paging
앞서 살펴본 Demand Paging은 크게 보면 physical memory를 캐시처럼 사용하는 것이다. 따라서 캐시 메모리의 특징인 locality를 적용할 수 있다.
- Spatial locality: 참조된 페이지 근처의 페이지는 함께 참조될 가능성이 높다.
- Temporal locality: 최근에 참조된 페이지는 다시 참조될 가능성이 높다.
이 지역성에 대한 예시는 도서관으로 생각할 수 있다. 도서관에 가서 운영체제 책을 찾는다고 하면 하나만 찾지는 않을 것이다.
일단 총류에 가서 운영체제 코너에 간 다음 그 근처에서 제일 괜찮아 보이는 책들을 모두 찾을 것이다. 이것이 바로 spatial locality 즉 공간적 지역성이다.
운영체제 책을 한번만 보고 모든 내용을 깨달을 순 없을 것이다. 분명 봤던 내용들도 다시 봐야 이해가 간다. 이것이 바로 temporal locality 즉 시간적 지역성이다.
paging은 이전 memory management 포스팅에서도 봤듯이 infrequent하다. 따라서 이러한 접근이 가능한 것이다.
그럼 구체적으로 어떻게 Swapping이 실행될까?
swapping의 방법: valid-invalid bit
필요한 page가 main memory에 있는지 아닌지 어떻게 확인할까? 바로 valid-invalid bit를 활용한다.

처음에 paging 요청이 들어오면 valid-invalid bit는 0이다. 즉 main memory에 해당 Page가 없다는 것이다.
따라서 TLB를 보고 cache에 있는지 확인을 한다.
만약 TLB 에도 없다면 TLB miss 이므로 page table을 확인한다. 이때 main memory에 없기 때문에 또 miss가 난다.
그럼 cpu는 운영체제에게 요청을 한다. "야 나 이 page가 없어. 올려줘"
운영체제는 main memory에 올려주기 전에 확인을 한다.
1. 이 page가 사용 가능한 logical memory 범위를 넘어서 invalid 한가? 즉 memory protection fault 인건가?
2. disk에는 있는데 physical memory에 없어서 invalid한가? 즉 page fault인가?
운영체제는 2번 상황에서만 main memory에 Page를 올려준다. 즉 page fault일 때만 동작한다.
page fault
main memory에는 없고 하드디스크에는 있는 상황
page fault가 발생하면 os는 page fault handler를 실행시킨다.
page fault handler는 invalid 였던 page table entry에 memory에 page를 넣고난 후 valid로 바꾼다. 그 후 다시 process를 시작한다.
demand paging with page fault
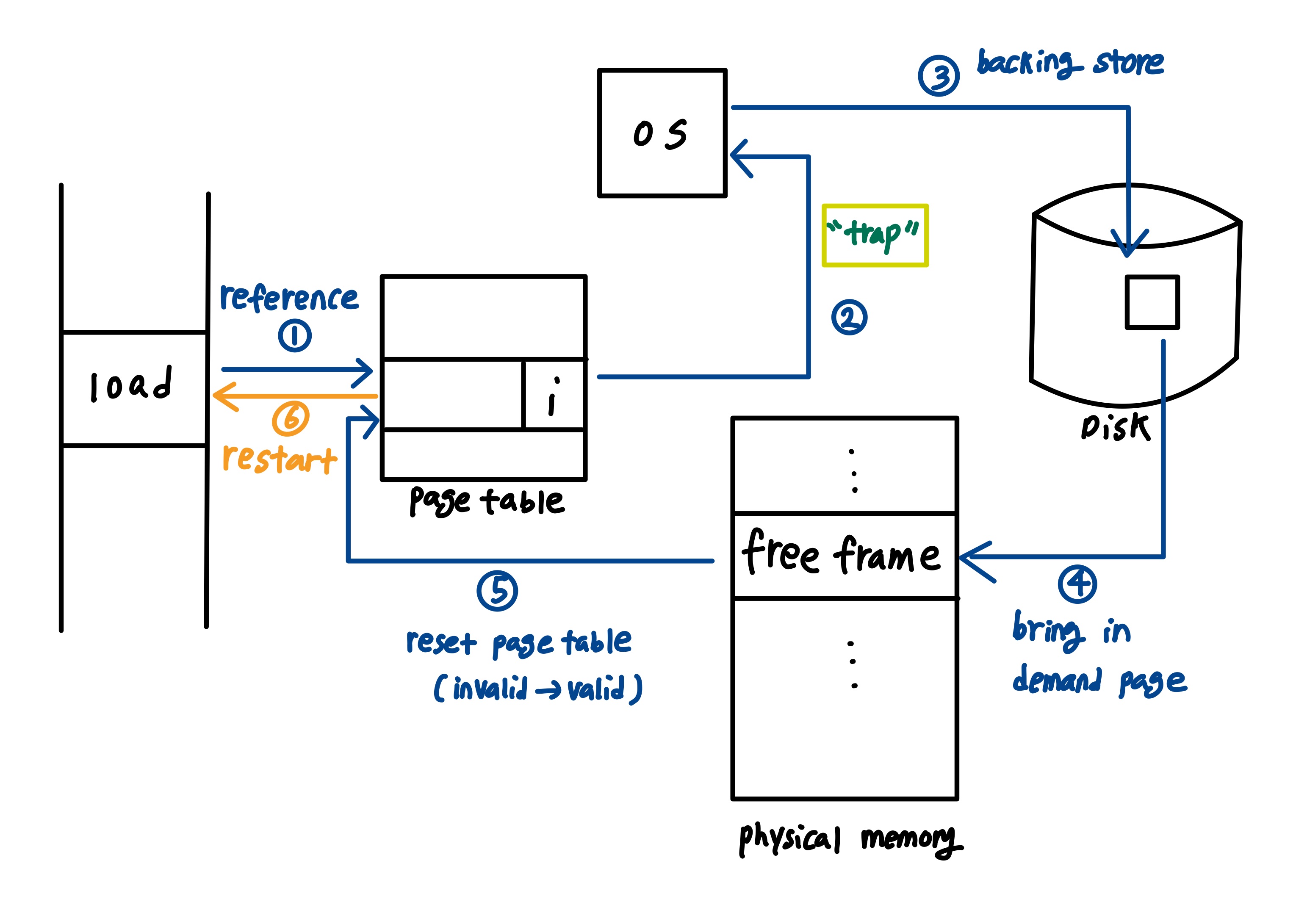
0. TLB에서 찾아서 있다면 바로 memory에 접근하고, TLB miss가 나는 경우 page table을 찾는다.
1. page table에서 invalid 한 page를 reference한다.
2. cpu는 찾을 수 없는 메모리를 trap을 걸어 os에게 요청한다.
3. os는 하드디스크로 가서 demanded page를 찾는다.
4. 빈 frame에 해당하는 page를 mapping 해서 올려준다.
5. main memory에 이제 해당 page가 들어왔으니, page table bit를 valid로 바꾼다.
6. fault가 발생했던 process를 다시 실행시켜 다시 1번으로 돌아간다.
여기서 문제는 4번이다. 이때 만약에 free frame이 없다면 어떻게 교체를 할까? 가장 안쓰이는 page를 disk로 내려 보내고 남은 자리를 차지한다. 즉 locality를 사용하여 과거에 사용되었던 이력을 보고 내린다.
이렇게 page를 교체하는 작업을 page replacement라고 한다.
이러한 page replacement는 disk, 즉 I/O 작업이기 때문에 효율성이 굉장이 중요하다.
Page Replacement Algorithms
위에서 설명한대로, 어떤 page를 disk로 보낼지 결정하는 알고리즘이다.
이 알고리즘의 목표는 page fault rate를 낮추는 것, 즉 page fault 발생 빈도를 줄이는 것이다.
FIFO
첫번째로 올라온 process가 제일 처음 swap out 된다. 즉 오래된 데이터를 내보낸다.
하지만 이는 효율성이 별로다. 데이터가 오래되었다고 해서 사용 빈도가 낮은 것을 뜻하는 것이 아니기 때문이다.
example) Belady's Algorithm
Optimal Algorithm
가장 사용 빈도가 낮은 것을 파악해서 swap out하자. 즉 가장 나중에 참조되는 것을 내리는 컨셉이다.
프로세스의 진행 순서가 다음과 같다고 하자.
1 2 3 4 1 2 5 1 2 3 4 5
frame이 4개라고 가정할 경우, page 교체는 다음과 같이 일어난다.
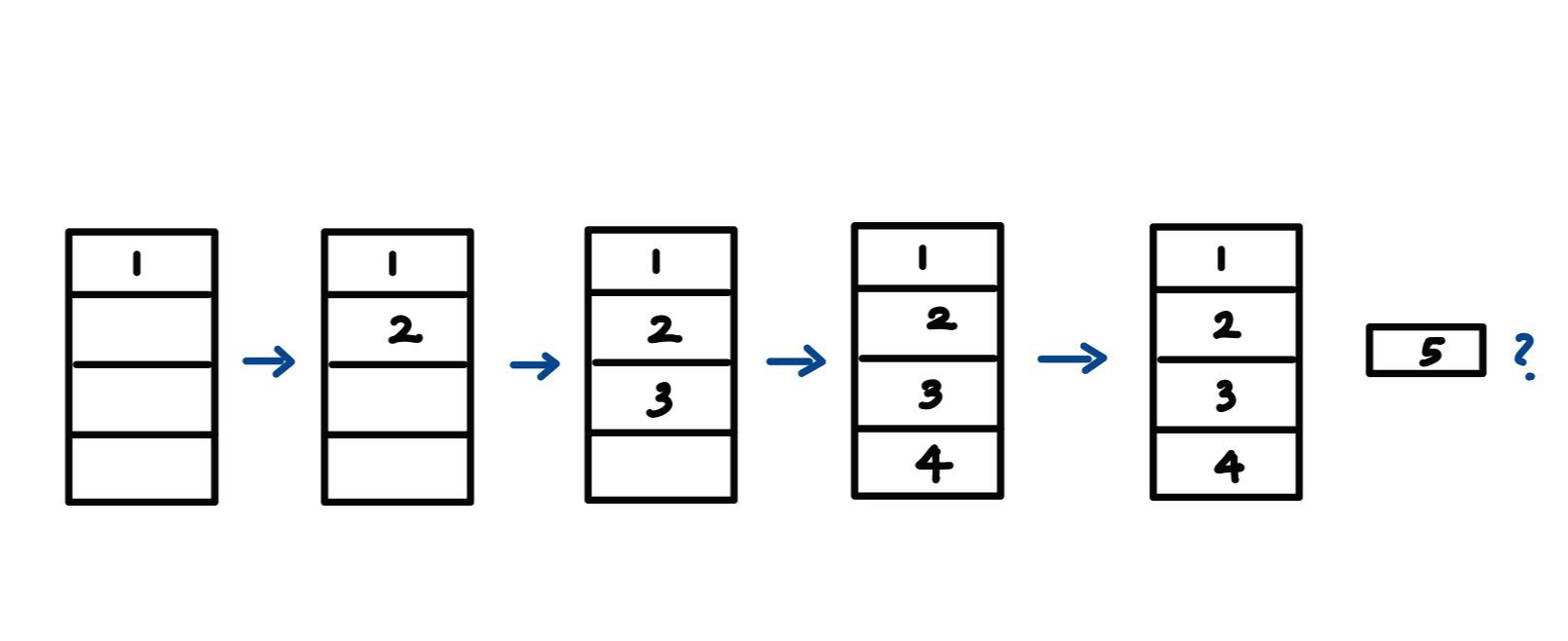
이때 process 5는 어떤 page와 교체를 해야 할까?
정답은 4와 교체하는 것이다.
1,2,3,4 중에서 가장 나중에 사용되는 것이 4이기 때문이다. 그렇다면 memory에는 (1-2-3-5) 가 채워진다.
그 후 4가 필요하게 되는데, 이때는 어떤 page와 교체를 할까?
이 경우 5를 제외하고는 모두 가능하기 때문에 제일 처음에 있는 1과 교체되어 (4-2-3-5) 로 채워진다.
따라서 이 경우 총 page fault는 6이다. (맨 처음에 없는 페이지를 부르는 것도 fault 이므로 count 해주기 때문)
이 알고리즘은 최적이긴 하지만 구현이 힘들다. 왜냐하면 참조하는 순서를 모두 알고 있어야 하기 때문에 오버헤드가 크기 때문이다.
Least Recently Used, LRU Algorithm
이 알고리즘은 과거의 이력을 보고 가장 오래전에 참조되었는 Page를 교체한다.
참조한지 오래된 page는 다시 참조될 가능성이 적기 때문이다.
따라서 프로세스의 진행 순서가 다음과 같다고 할 경우
1 2 3 4 1 2 5 1 2 3 4 5
위의 경우와 마찬가지로 다음과 같은 page 교체를 한다.
이때 process 5는 어떤 page와 교체를 해야 할까?
정답은 3이다.
5가 된 순간 가장 최근에 참조한 순서대로 (2-1-4-3) 이 된다. 따라서 오래된 이력인 3을 지운다.
그 후 3에서 다시 page fault가 발생하게 되고 이때 가장 최근에 참조한 순서는 (2-1-5-4) 이므로 4를 지운다.
이런식으로 page 교체를 현 시점에서 가장 오래전에 참조되었던 page를 교체한다.
이 방식은 optimal algorithm 보다는 page fault rate가 높지만 가장 합리적이고 구현이 가능하다는 점에서 주로 사용된다.
이때 최근에 참조된 page를 저장하는 방식은 두가지이다.
- time stamp
- stack
그 밖의 여러 알고리즘들
LRU clock, NRU, Counting Algorithm etc
LFU
가장 적은 참조 횟수를 가진 page와 교체한다.
하지만 어느시간에서만 집중적으로 쓰이고 그 뒤에서는 쓰이지 않는 page가 있다면, 이는 교체 대상이 되기 적절함에도 불구하고 참조횟수 count에 의해 교체되지 않는 비효율적인 상황이 발생하게 된다.
따라서 사용하지 않는다. 하지만 이러한 문제를 해결하기 위해 Aging 기법도 사용하기도 한다.
여기까지 모든 이해를 했다면 다음과 같은 의문이 든다.
"아니 그 순간에 필요한 page들만 올리는 것은 알겠음. 근데 한번에 몇개나 올릴 수 있는데?"
예를 들어 process가 10개이고 각 Process마다 10개의 Page가 있다면 전부 physical memory에 올리기 위해서는 총 100개의 frame이 필요하다.
하지만 memory가 가난해서 50개 밖에 없다면 낭패이다. 자 이제 이걸 어떻게 나눠줄까?
이를 위해 두가지 방식이 가능하다.
Allocation of Frames
1. Fixed Allocation
: 각 프로세스마다 동일하게 할당한다.
위와 같은 상황에서는 모두가 평화롭게 5개씩 가져가면 된다.
2. Priority Allocation
: 중요한 process에게는 더 많은 frame을 할당한다.
내가 지금 처리할 일이 많다면 필요하지 않은 process에게 frame을 할당해주는 것은 비효율적이기 때문이다.
그렇다면 이렇게 process마다 가질 수 있는 frame을 할당해준다면 swapping은 어떻게 정할까?
swapping을 위한 frame 선택도 두가지이다.
Global vs Local Allocation
1. Global
physical memory의 전체 frame을 대상으로 swapping의 대상을 찾는다.
예를 들어 교체 알고리즘을 LRU로 정한다면, 모든 프로세스에 대해서 가장 오래된 frame을 찾아 교체한다.
2. Local
process가 할당받은 frame을 대상으로만 swapping할 frame을 찾는다.
LRU의 경우, 특정 프로세스에 의해 할당된 자신의 frame 영역에 대해서 가장 오래된 frame을 찾아 교체한다.
기본적으로는 local allocation을 사용하지만, 이 방식은 문제가 있다.
바로 Trashing이라고 하는 것이다.
Trashing
process가 swapping으로 인해 busy해서 일 처리를 못하는 상황
즉 지나친 page fault로 인해 성능이 저하되는 문제이다.
local allocation으로는 frame을 교체하는 데 swap in, swap out을 계속해서 반복하기 때문에 시간을 다 써버릴 수 있다.
이때 page replacement algorithm을 잘못 한다면 계속 page fault가 발생하고 이러한 상황을 trashing이라고 한다.
마찬가지로 프로세스에게 할당된 frame이 작아도 trashing 현상이 발생할 수 있다.
일반적으로 멀티 프로그래밍은 cpu utilization을 높여주는 역할을 한다.
하지만 멀티 프로그래밍의 프로세스 수가 많을 수록 cpu utilization이 비례하여 항상 증가하지는 않는다.

프로세스의 수가 많을 수록 cpu는 처리해야 할 일이 많아진다. 따라서 cpu 활용도가 높아진다.
하지만 프로세스의 수가 많아질 수록 한정된 physical memory 위에 올리기 위해서 각 Process마다 할당받는 frame 수를 줄여야 한다.
따라서 frame수가 작아지니 자연스럽게 page fault rate가 증가하기 마련이고, 어느 순간 cpu들은 작업을 하지 못하고 이 page fault에만 매진하여 process 작업을 처리하지 못하게 된다. 따라서 cpu utilization이 감소하게 된다.
그렇다면 이 문제는 어떻게 해결할 수 있을까?
이미 frame 수는 부족하기 때문에 단순하게 frame수를 늘리는 방법은 사용할 수 없다.
결국 process 수를 줄여서 남은 process에게 더 많은 frame을 할당하는 방식으로 해결해야 한다.
현재 os는 이를 바탕으로 한 Page fault frequency scheme을 사용한다.
Page-Fault Frequency Scheme
page fault rate에 따라 유기적으로 frame 수를 조절하는 방법이다.
page fault rate가 크다는 것은 frame 수가 작다는 뜻이므로 frame 수를 늘려주고
page fault rate가 작다는 것은 놀고 있는 frame 수가 많다는 것이므로 frame 수를 줄여서 다른 Process에게 할당해줘야 한다.
'STUDY > 운영체제' 카테고리의 다른 글
| Secondary Storage Architecture (0) | 2022.03.14 |
|---|---|
| Implementing File System (0) | 2022.03.05 |
| memory management strategies2: page table의 구현 (0) | 2022.02.16 |
| memory management strategies (0) | 2022.01.10 |
| deadlocks (0) | 2022.01.02 |