process가 무엇인가?
process는 프로그램 실행 흐름의 가장 기본적인 단위이다.
다들 이렇게 설명하는데 사실 뭔 소린지 이해가 안갈 수 있다.
그럴때는 프로그램 실행을 위한 작업의 대상, 즉 os가 scheduling하는 대상이라고 생각하면 쉽다.
process
- 프로그램의 실행 단위
- 프로그램 안에서 흐름을 제어하는 캡슐화 단위
- dynamic and active entity
- 실행과 스케쥴링 단위
process address space
process가 메모리에 저장되는 공간은 어디일까?
memory의 구조는 낮은 주소부터 code, data, heap, dynamic으로 구성되어 있다.
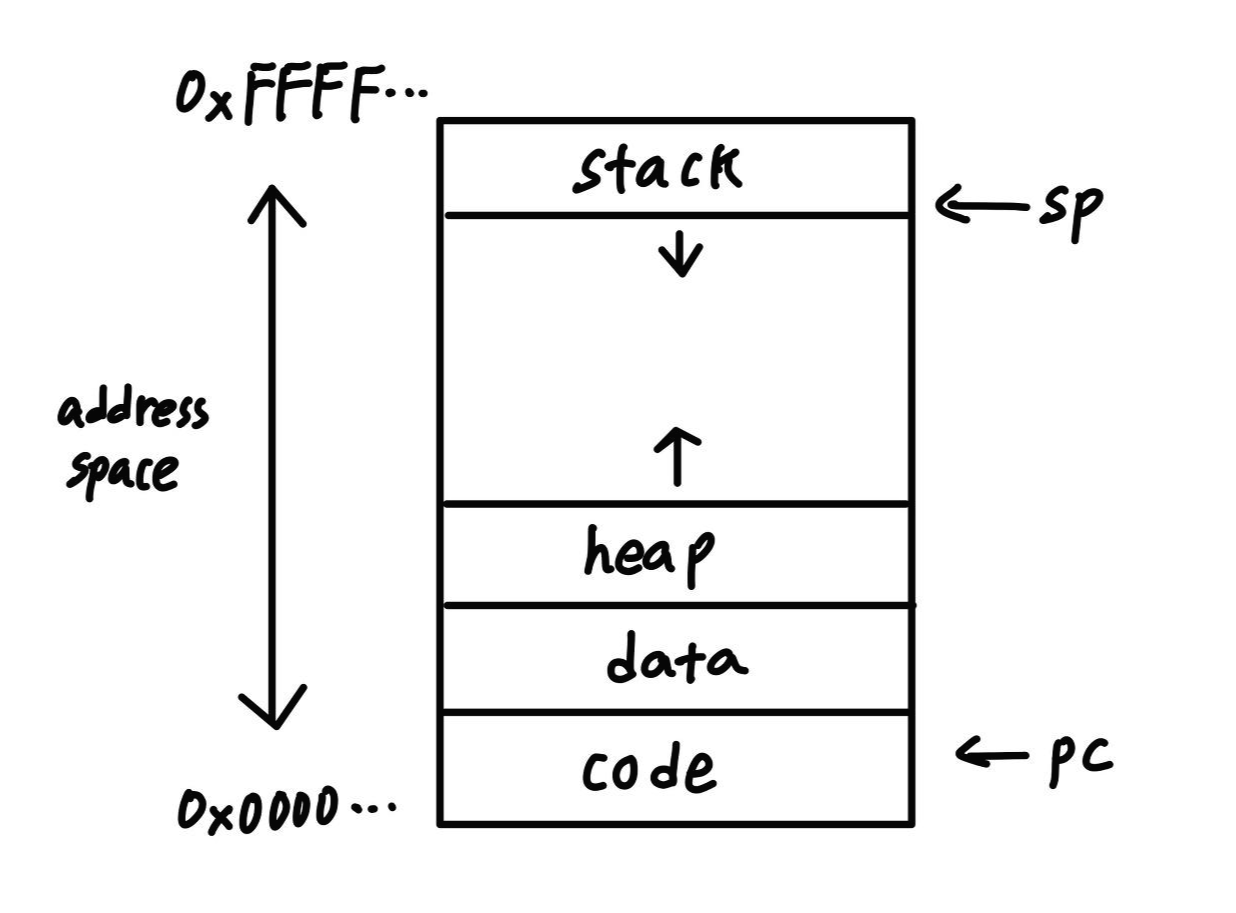
code: text segmentn로 기계어들이 저장되어 있다.
data: 변하지 않는 static data들은 여기에 저장된다. 즉 전역변수나 static으로 선언된 변수들은 여기에 저장된다.
이 변수들은 프로그램이 완전히 종료되어야 사라진다.
heap: 동적으로 할당한 변수들은 여기에 저장된다. 즉 메모리의 크기를 실행할 때 결정하는 것이다.
stack: 함수 호출시 일반 변수들, 즉 지역 변수와 매개변수들은 여기에 저장된다. 함수 호출이 끝나면 stack pointer가 이동하여 메모리에서 내려간다.
보통 리눅스에서는 프로세스에게 4GB의 가상공간을 할당하고 0~3GB 는 사용자 공간, 나머지 3~4GB는 커널 공간으로 할당한다. 이때 사용자 공간이란 code, data ~ stack 까지의 영역을 말한다.
예를 들어
int main() {
int i=10;
int arr[i];
return 0;
}뭐 이런 코드가 있다고 하는 경우 arr[i]는 메모리의 어디에 생길까?
프로그램 실행 전에는 i의 값을 모르기 때문에 실행 전에는 결정할 수 없다. 런타임에 i=10을 하고 나서 결정되기 때문에 heap 영역에 저장된다.
process state
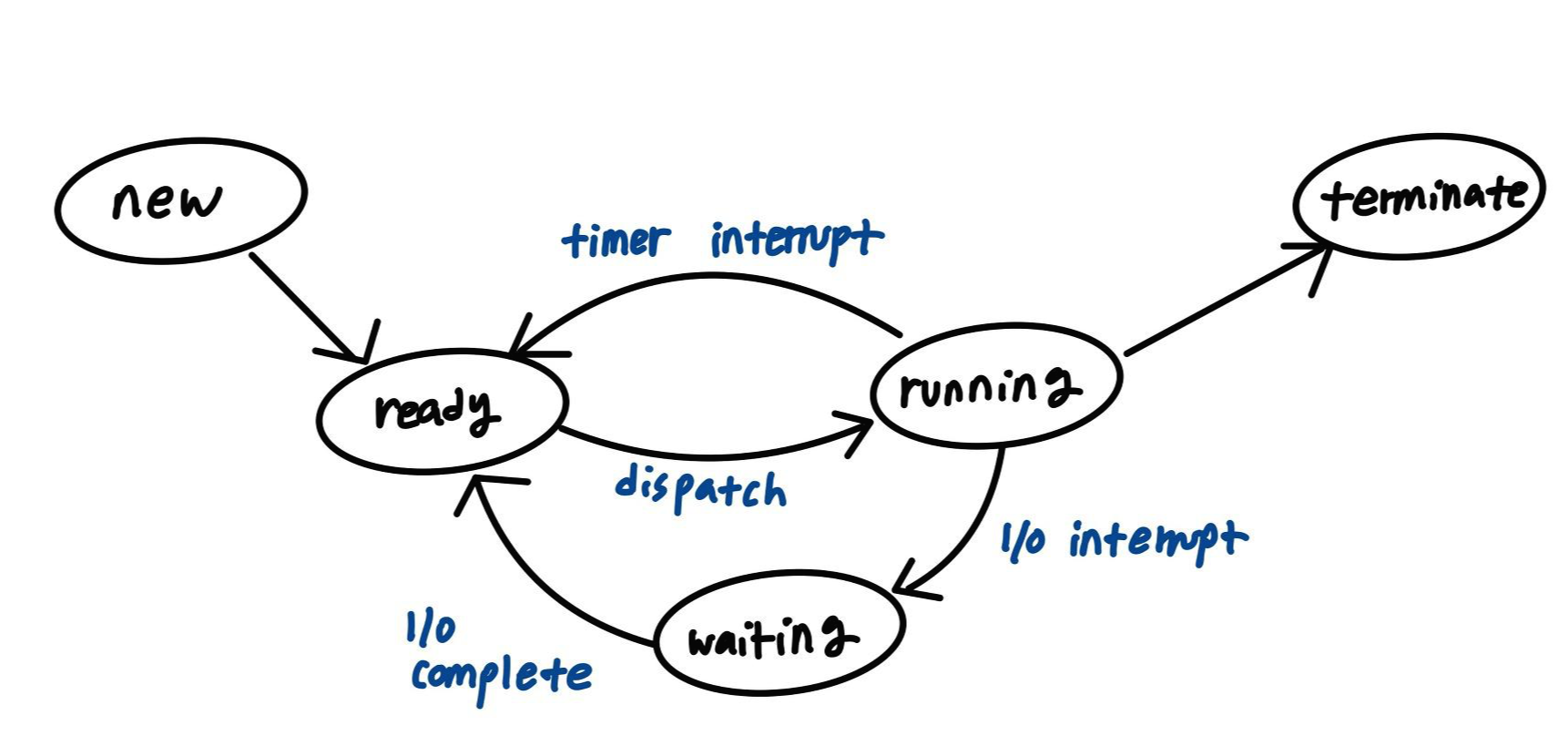
프로세스는 실행하면서 상태를 변화시킨다.
-new: being created. 처음으로 프로세스가 생기는 상태
- running: Instructions being executed. 프로세스가 실행중인 상태
즉 cpu가 자원을 써서 process를 처리하는 상태이다.
- waiting: Waiting for same event to occur. 프로세스가 잘 실행되다가 멈춘상태이다. 예를 들면 i/o interrupt와 같은 event가 발생했을 경우에는 process가 cpu자원을 사용하지 않고 waiting 상태로 물러난다.
예를 들어, 사용자 입력을 기다리는 등 I/o 작업에 아주 긴 시간이 걸린다고 생각해보자. 이때 cpu자원을 계속 사용하게 되면 자원이 낭비된다. 이를 busy waiting이라고 한다. cpu 자원을 사용하면서 기다리는 것이다.
하지만 cpu는 노예와 마찬가지라서 1분 1초도 쉬게할 수 없다. 따라서 waiting 상태로 변화시켜 다른 작업을 할 수 있도록 cpu를 조절해야한다.
그러다 갑자기 i/o 작업이 끝났다면 어떻게 될까? 다시 cpu의 자원을 받아 일을 해야한다. 이를 위한 상태가 ready이다.
- ready: waiting to be assigned to a process. 프로세스가 실행이 가능한 상태
즉 ready는 스케쥴링의 대상이 된다.
이때 중요한 점은 running 상태에서 아무 interrupt가 오지 않았는데도 ready상태로 변할 수 있다는 것이다. 이는 scheduling에 필요한 부분이다. cpu는 context switch를 통해 여러작업을 번갈아 수행한다. 처리율이 높아지기 때문이다. 하지만 어떤 한 작업이 아주 오래 걸린다고 생각해보자 이 경우 처리율은 높아지지 않는다. 따라서 timer interrupt를 걸어서 어떤 한 작업이 너무 오래 process를 점유하지 않도록 해준다. process에게 할당된 time quantum을 다 사용해서 timer interrupt가 온 경우 process는 running에서 ready로 전환한다.
- terminated: finished execution. 작업을 다 끝내고 종료된 상태
process control block, PCB
프로세스 정보는 블록 단위로 저장한다. 이를 관리하기 위한 운영체제의 kernel 자료구조이다.

pcb에는 어떤 정보들이 저장되는가?
- process state
- program counter; 프로세스 다음에 실행할 명령어의 주소도 저장한다.
- cpu register
- cpu scheduling information; 어떤 명령어부터 실행할지에 대한 정보도 저장한다.
- memory-management information; 해당 프로세스의 주소 공간이나 메모리를 관리하기 위한 정보이다.
- accouting information; 프로세스의 계정 정보 또한 저장한다. 계정 정보란 프로세스 고유의 정보들이다. 예를 들면 page table, queue pointer와 같은 정보들이다.
- I/O status information; 프로세스에 할당된 입출력 장치 목록이나, 열린 파일 같은 정보들이다.
PCBs and hardware state
process가 실행중이면 프로세스 정보는 다 cpu register에 저장된다.
program counter, stack pointer, register 등등
process가 ready나 waiting 상태이면 프로세스 정보는 PCB에 저장한다.
그러다 다시 running이 되면 PCB의 정보를 register로 load한다.
이러한 정보 저장을 번갈아가면서 실행하는게 컨텍스트 스위칭이다.
cpu switch == context switch
cpu를 하나의 process에서 다른 process로 전환하는 작업이다.
당연히 process의 정보를 PCB와 register로 저장했다 로드했다 하는 작업은 오버헤드가 크다. 하지만 이 context switch를 했을 때의 time sharing과 처리량이라는 장점이 더 크기 대문에 필수적이다.
그럼 누가 PCB들을 이동해줄까?

PCB and queue
waiting이나 ready에서는 queue들로 PCB를 저장하는데, os가 PCB를 queue에서 다른 queue로 이동시킨다.
queue들은 여러 종류가 있다.
process scheduling queues
- Job queue: 모든 프로세스를 저장한 queue. 당연히 terminated는 저장하지 않는다.
- ready queue: 프로세스들이 cpu자원할당을 기다리는 queue
- device queue: wait 상태의 PCB들을 저장하는 queue
그럼 이러한 queue에서 어떤 process들을 먼저 수행해야 하는가?
이는 scheduler 운영체제가 결정한다.
scheduler: ready queue에서 어떤 프로세스를 실행해야 하는지 순서를 결정한다.
- Long term scheduler(job scheduler): 여러 프로세스에서 어떤 프로세스, 또는 프로세스들을 메모리에 올릴 지 결정한다.
- Short term scheduler(cpu scheduler): 어떤 프로세스 하나를 ready 상태에서 running으로 변경할지 결정한다.
Long term scheduler
: ready queue에 무엇을 올릴까?
multi-programming의 정도를 결정한다. 최근에는 virtual memory management로 인해 사라졌다.
i/o-bound와 cpu-bound의 mixture이다.
time sharing system들은 long term scheduler가 없다. 예를 들면 unix
short term scheduler
: cpu에 무엇을 올릴까?
항상 fast 해야한다.
scheduling에는 원칙이 있다.
- cpu bound: cpu utilization, throughput
- I/O bound: response time, turn-around time, waiting time
medium term scheduler
: multi-programming의 degree를 낮춘다.
프로세스 수가 많으면 main memory에 공간이 없다. 따라서 일부 process를 swap device로 보냈다가 프로세스 수가 줄어들면 다시 불러와야 한다. 이때 사용되는 것이 swapper이다. 일시적으로 메모리에서 프로세스를 지워준다.
process creation
: parent process create child process => tree
linux/unix에서는 fork() 를 통해 process를 생성한다.
resource sharing
fork()를 통해 parent, child process를 생성하면 프로세스들은 자원을 공유하지 않는다.
execution
execute concurrently
wait() 으로 process가 종료되는 것을 기다릴 수 있다. 즉 순서를 조절 가능하다.
#include <stdio.h>
#include <unistd.h>
int main() {
int pid;
if((pid=fork())==0){
// child process
}
else{
// parent process
}
}fork() 를 하게 되면 return 값으로는 정수형의 process id가 반환된다.
이때 child process는 pid가 0이 된다. 따라서 이를 기준으로 if-else문을 작성하면 multi-process program을 만들 수 있다.
이때 parent process와 child process는 어떤 순서로 실행될까?
정답은 모른다!이다. 왜냐면 이러한 실행 순서는 scheduler가 결정하기 때문에 순서는 항상 달라질 수 있음을 기억해야한다.
따라서 실행 순서를 조절하고 싶을 때는 wait() 과 같은 sys call을 따로 써서 조절해야 한다.
process termination
정상 종료 => exit()
output data를 child to process
운영체제가 resource를 할당해제 한다. 즉 deallocate
비정상 종료 => abort()
parent가 child를 종료시킨다.
parent가 종료되면 child도 따라서 종료된다.
cooperating process
- independent process: 다른 프로세스의 실행에 영향을 주고받지 않음
- cooperating process: 프로세스끼리 영향을 주고 받는다.
cooperating process를 하면 어떤 장점이 있을까
- information sharing: 예를 들면 파일에 동시접근하여 데이터를 접근하는 경우
- computation speed up: 각 작업을 divide and conquer해서 빠르게 수행 가능하다.
- modularity: 시스템 기능을 여러 프로세스나 스레드로 나누어서 협력할 수 있다.
- convenience: 협력하면 사용자의 multi-tasking이 좋아지므로 편리함이 늘어난다.
이렇게 process끼리 협력하여 정보를 주고받기 위해서는 특별한 방법이 필요하다. 왜냐하면 process들은 운영체제의 memory protection management 때문에 서로에게 직접 통신을 할 수 없기 때문이다. 따라서 운영체제의 도움이 필요하다. 이를 IPC라고 한다.
IPC, inter process communication
프로세스 간의 동작을 동기화하여 통신을 한다. IPC에는 두가지 모델이 있다.
- message passing
- shared memory

message passing
전달하려는 message, data를 kernel에 저장했다가 다시 다른 프로세스에게 이를 전달하는 방식이다.
linux에서는 pipe, FIFO, message queue 등으로 이를 구현가능하다.
message passing은 동기화를 os가 알아서 처리해준다.
예를 들어 A가 fifo에서 B가 보낸 메세지를 read() 하는데 B가 아직 메세지를 보내지 않았다고 해보자. 이 경우 동기화 문제가 발생할 수 있다.
이때 os는 A를 waiting 상태로 보내 B의 write를 대기하도록 동기화를 맞춰준다.
사실상 개발자에게 가장 까다로운 동기화 작업을 안해도 되는 것이니 편리하다.
하지만 message passing은 보내고자 하는 데이터가 많은 경우 오버헤드가 발생할 수 있다. 당연함.
수신자를 정하는 direct communication, 수신자를 정하지 않고 Port를 정하는 indirect communication
shared memory
process가 모두 접근 가능한 메모리 공간을 만든다. bounded buffer의 형태가 대부분이다.
kernel의 도움 없이도 통신이 가능하기 때문에 오버헤드가 작고 속도도 빠르다.
하지만 os가 동기화를 해주지 않기 때문에 직접 프로그래밍을 통해 동기화를 맞춰야한다. semaphore나 mutex lock 등등의 기법을 사용할 수 있다.
동기화는 뒤에 하나의 포스팅으로 자세히 설명할 예정이지만 간단하게 짚고 넘어가보도록 하겠다.
shared memory가 bounded buffer이기 때문에 producer-consumer problem의 가능성이 있다.
자료구조는 circular queue로 구현된다. 즉 buffer size - 1의 데이터들을 사용가능하다.
동기화를 맞춰주지 않으면 read와 write를 마음대로 하기 때문에 문제가 생긴다.
또한 while문을 사용하여 empty, full의 경우를 처리하면 cpu 자원을 사용하는 busy waiting 문제가 생긴다.
따라서 semaphore를 사용하여 busy waiting, synchronization 두가지의 문제를 해결해야 한다.
'STUDY > 운영체제' 카테고리의 다른 글
| synchronization (0) | 2021.12.02 |
|---|---|
| process scheduling (0) | 2021.12.01 |
| multi-thread programming (0) | 2021.11.30 |
| os system structure (0) | 2021.11.28 |
| about operating system (0) | 2021.04.05 |